Understanding the relationship between sensory uncertainty and confidence
In humans and machines
Sensory input is often ambiguous, leading to uncertain interpretations of the external world. Estimates of perceptual uncertainty might be useful in guiding behavior, but it remains unclear whether humans explicitly represent uncertainty in naturalistic settings, and whether any such representations are normatively correct. One of bottlenecks here is the lack of models that can estimate uncertainty faithfully. Current state-of-the-art AI models (including LLMs) are notoriously miscalibrated, and often overconfident. In this project, we developed a class of task-optimized models that generate probability distributions over perceptual estimates. To assess whether human uncertainty representations align with the model’s, we compared human confidence judgments, which might indirectly reflect uncertainty representations, to confidence judgments extracted from the model’s uncertainty. We found that in both sound localization and pitch perception, human confidence varied systematically, being lower for stimuli that produced more variable estimates across trials. Human confidence tracked model confidence across conditions, suggesting that human uncertainty representations accurately reflect the actual uncertainty of perceptual estimation. The modeling framework is extensible to other perceptual domains.
Here is a quick overview below. For more details, do check out our recent preprint (Govindarajan et al., 2025).
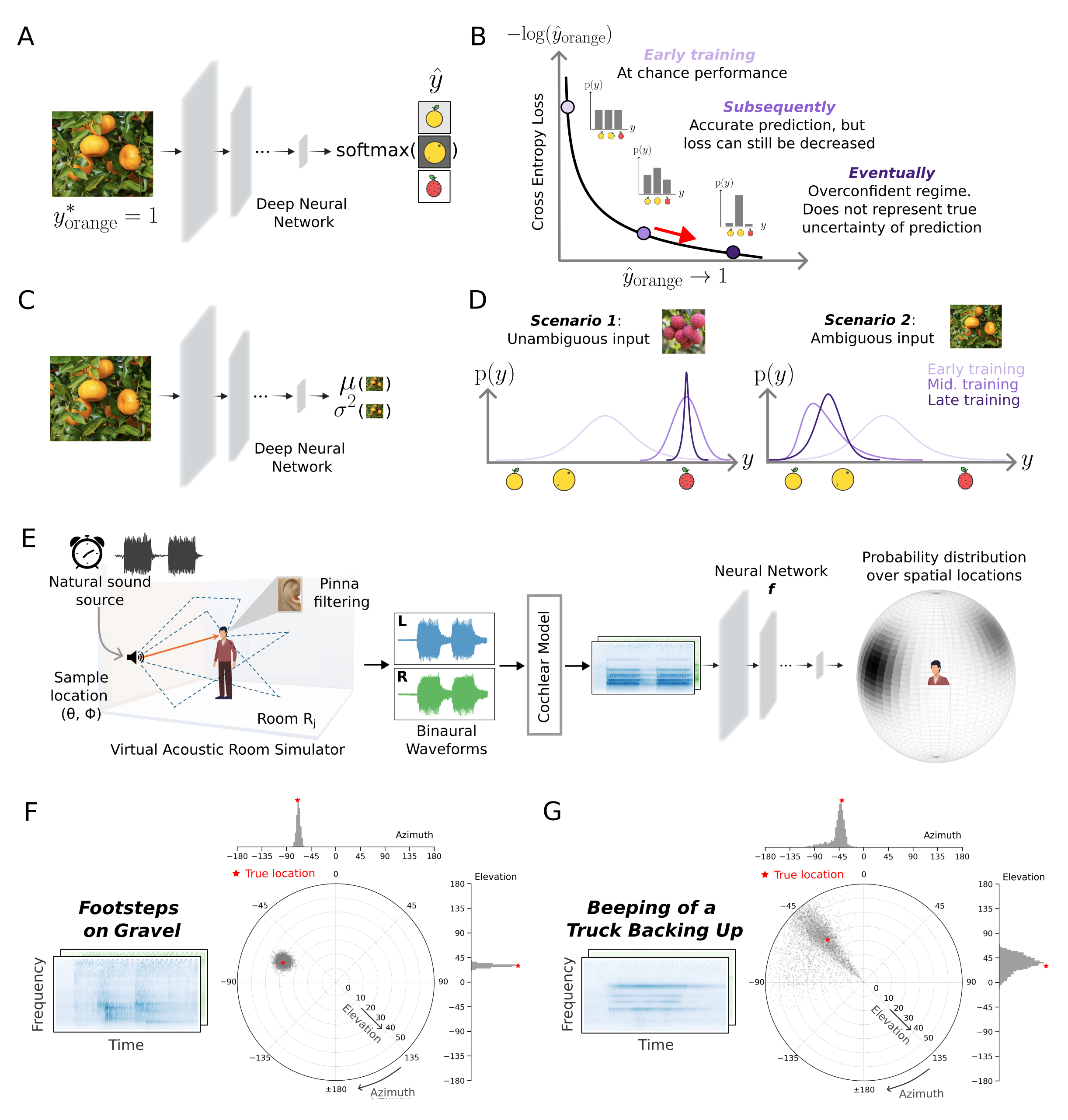
Conceptual sketch and application of the proposed computational framework to sound localization. A. Canonical neural network for classification. B. Schematic of consequence of training a model with the cross-entropy loss function. C. Neural network that outputs parameters of a univariate Gaussian. D. When optimized with a maximum likelihood loss function, the model should learn to predict narrow distributions when actual uncertainty is low, and wider distributions when actual uncertainty is high. E. Model framework applied to sound localization. Training data is generated using a room simulator that yields the binaural audio signals that would enter the ears of a person at a particular location in a room listening to a sound at another particular location. The audio signals are passed through a fixed model of the cochlea followed by a neural network. The neural network predicts the parameters of a von Mises mixture distribution of locations over a sphere surrounding the listener. F. Posterior distribution for trained model for the sound of footsteps on gravel. This sound can be localized relatively precisely, and the model accordingly produces a narrow posterior. The posterior is visualized with Monte Carlo samples plotted in polar coordinates, with azimuth on the circular axis, elevation on the radial axis, and marginals shown as top (azimuth) and right (elevation) histograms. G. Posterior distribution for trained model for the beeping of a truck backing up. This sound’s location is relatively ambiguous, and the model accordingly produces a broader posterior.
References
2025
bioRxiv
Task-optimized models of sensory uncertainty reproduce human confidence judgments
Lakshmi Narasimhan Govindarajan, Sagarika Alavilli, and Josh McDermott
@misc{uncertainty25,title={Task-optimized models of sensory uncertainty reproduce human confidence judgments},author={Govindarajan, Lakshmi Narasimhan and Alavilli, Sagarika and McDermott, Josh},year={2025},volume={10.1101/2025.10.31.685933},}